
前言:本系列的文章有点难度,建议零基础小白先从小白学python系列的文章开始学习,并且,本系列的文章,博主只是讲解一些用来娱乐的知识点。知识点可能不会很全,还请见谅。
太聪明了怎么办?那就给脑子灌爬虫的知识点,让自己更加聪明 !!!


1.请求网址 -------request url
2.请求方法 -------- request methods(如get,post)
3.请求头-------request header
4.请求体 ---------- request body
ok,知道以上部分东西以后我们就可以开始爬虫了,由于本系列的文章只是用于娱乐,因此博主只会给大家讲解一些很浅,且容易吸收的东西。
那么时间有限今天就先简单讲一个爬取音乐的案例。
第一步,百度搜索网易云音乐
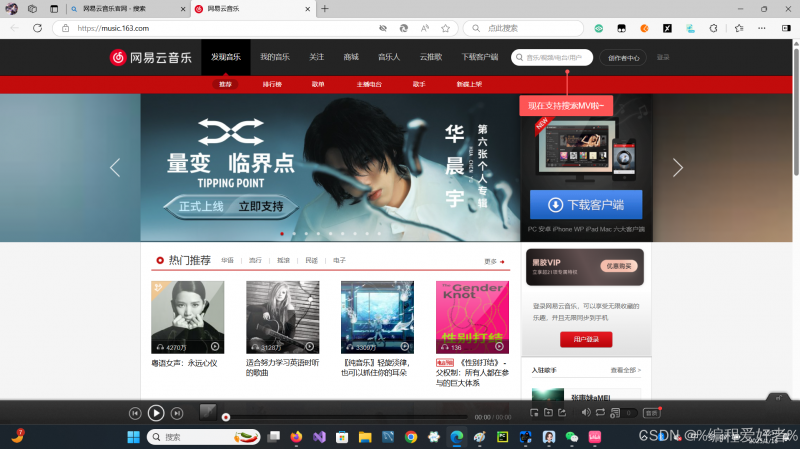
这里博主使用的是edge浏览器,当然这里博主也推荐大家使用谷歌浏览器,这个要比edge好用。
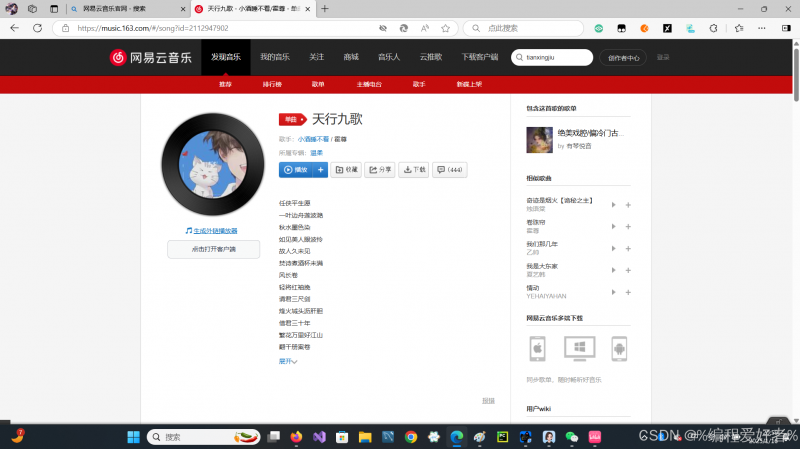
进入到这个页面后先点击播放,然后再按f12或者fn + f12(这个是笔记本电脑的) ,也可以鼠标右击点击检查
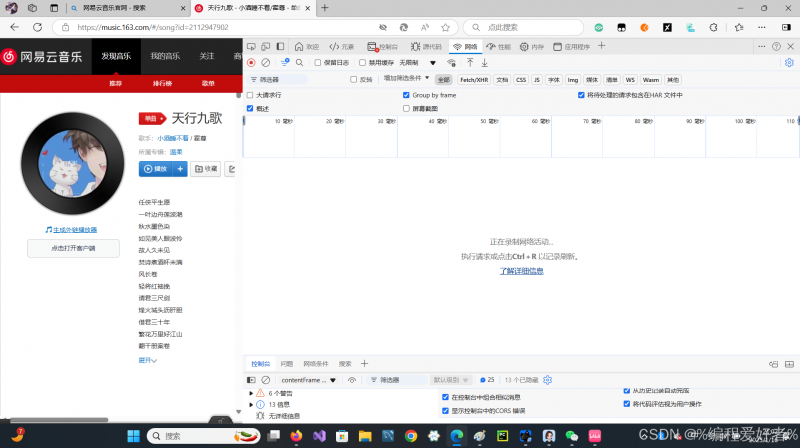
选择网络,然后我们播放音乐

在这么多数据包中找到我们要爬的数据包,那么这里我们要找到对应的数据包,那么怎么找到音乐的数据包呢,首先音乐是有声的,我们可以在上面的分类中找到媒体类

通过这里的数据包名称和大小我们可以确定,这应该是一个完整的数据包,但具体是不是音乐呢我们爬下来后才知道。
那么找包的部分已经结束,我们来到代码部分。

这个就是简单爬虫的代码,对于小白而言,直接当成模板记就行
接下来我们来找url这一部分的字符串
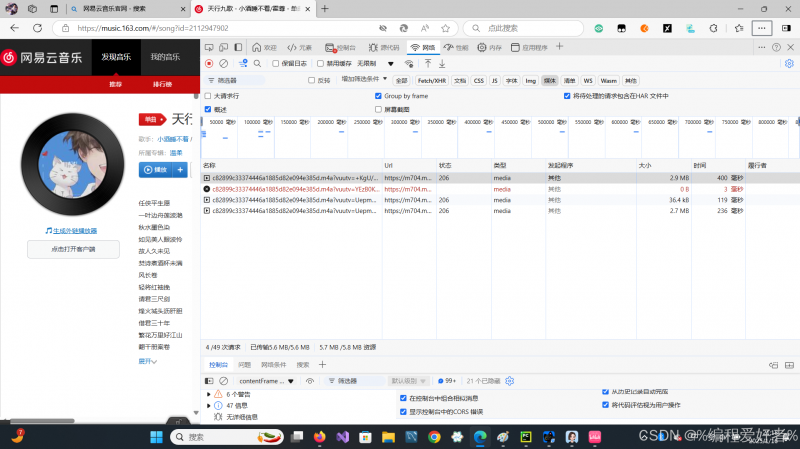
点击这些包中的一个
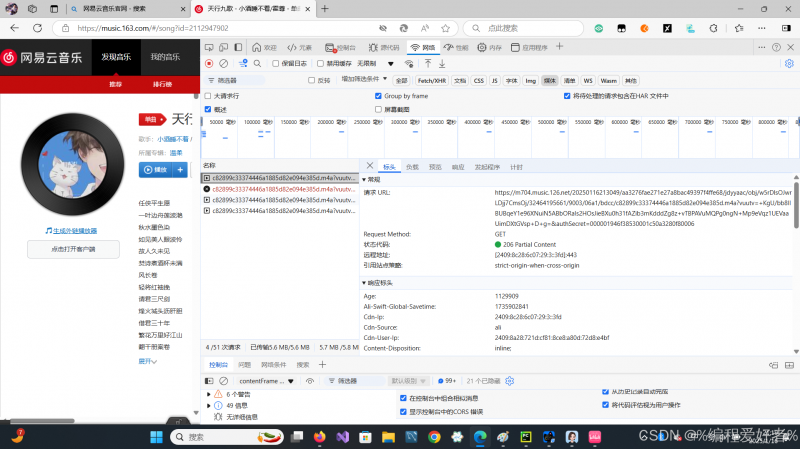
选择标头

复制这些到url中
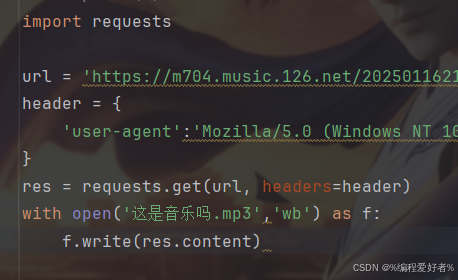
运行代码
本篇文章的内容就先到这里,我们下期文章再见!!!