目录
一、新词发现
1.新词发现的衡量标准
① 内部稳固
② 外部多变
2.示例
① 初始化类 NewWordDetect
② 加载语料信息,并进行统计
③ 统计指定长度的词频及其左右邻居字符词频
④ 计算熵
⑤ 计算左右熵
编辑
⑥ 统计词长总数
⑦ 计算互信息
⑧ 计算每个词的价值
⑨ 新词检测
编辑
二、挑选重要词
1.数学角度刻画重要词
例:
编辑
TF·IDF其他计算方式
2.算法特点
3.算法示例
① 构建TF·IDF字典
② 根据tf值和idf值计算tf·idf
③ 计算给定语料库中每个文档的TF-IDF值
④ 提取每个文本的前top个高频词
⑤ tf·idf的计算和使用
4.TF·IDF应用 —— 搜索引擎
① 对于已有的所有网页(文本),计算每个网页中,词的TF·IDF值
② 对于一个输入query(查询)进行分词
③ TF·IDF实现简单搜索引擎
5.TF·IDF应用 —— 文本摘要
① 加载文档数据,并计算每个文档的TF·IDF值
② 计算生成每一篇文章的摘要
③ 生成文档摘要,并将摘要添加到原始文档中
④ TF·IDF实现简单文本摘要
6.TF·IDF应用 —— 文本相似度计算
① 加载文档数据并计算TF-IDF值
② 将文章转换为向量
③ 文档转换为向量表示
④ 计算两个向量间的余弦相似度
⑤ 计算输入文本与语料库所有文档的相似度
⑥ TF·IDF实现文本相似度计算
7.TF·IDF的优势
① 可解释性好
② 计算速度快
③ 对标注数据依赖小
④ 可以与很多算法组合使用
8.TF·IDF的劣势
① 受分词效果影响大
② 词与词之间没有语义相似度
③ 没有语序信息
④ 能力范围有限
⑤ 样本不均衡会对结果有很大影响
⑥ 类内样本间分布不被考虑
死亡不是生命的终点,被遗忘才是
—— 24.12.21
引言
假设没有词表,如何从文本中发现新词?
随着时间的推移,新词会不断地出现,固有词表会过时
补充词表有利于下游任务
词相当于一种固定搭配
① 内部稳固
词的内部应该是稳固的,用内部稳固度/互信息衡量
内部稳固度/互信息:词语中几个字的固定搭配出现的次数除以词语中每个字单独出现的概率的乘积
公式:
n:词语中字的个数,词语的长度;
p(W):词语中几个字的固定搭配词语的出现次数;
p(c1)…p(cn):词语中每个字在词表中单独出现的概率
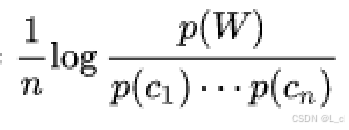
② 外部多变
词的外部应该是多变的,用左右熵衡量
左右熵: 将词语外部出现的所有字再除以出现的总词频数,得到出现某个字的频率pi,代入公式进行求和后取反,得到词语两边的左右熵,词语的外部两侧出现一个固定字的频率应该较低,换句话说,词的外部应该是多变的,而不是固定的,左右熵的值大小可以衡量词的外部值是否多变,左右熵的值越大,词的外部越多变
用两个指标计算分数,根据分数衡量一些文字组合是否是新词
公式:
pi:词语后出现某个字的频率,词语外部出现的所有字除以出现的总词频数
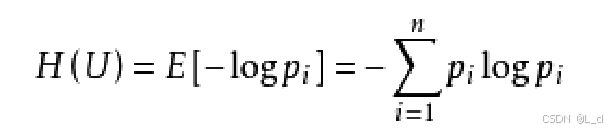
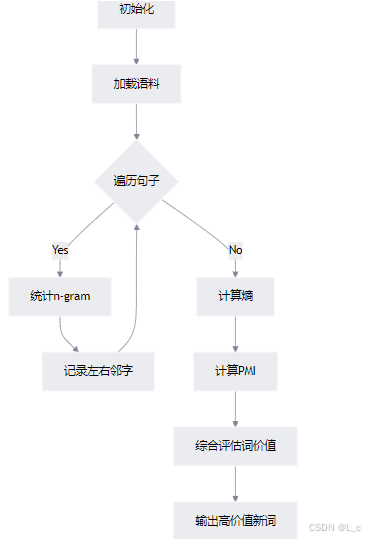
① 初始化类 NewWordDetect
Ⅰ 初始化参数:
设置词语最高长度max_word_;ength为5个字符
初始化三个字典:word_count 统计词频,left_neighbor 和 right_neighbor 分别记录每个词的左邻词和右邻词
Ⅱ 加载语料库:调用 load_corpus 方法加载语料库数据
Ⅲ 计算指标:计算calc_pmi互信息(内部稳固度),calc_entropy熵,以及cal_word_values词的价值
② 加载语料信息,并进行统计 load_corpus
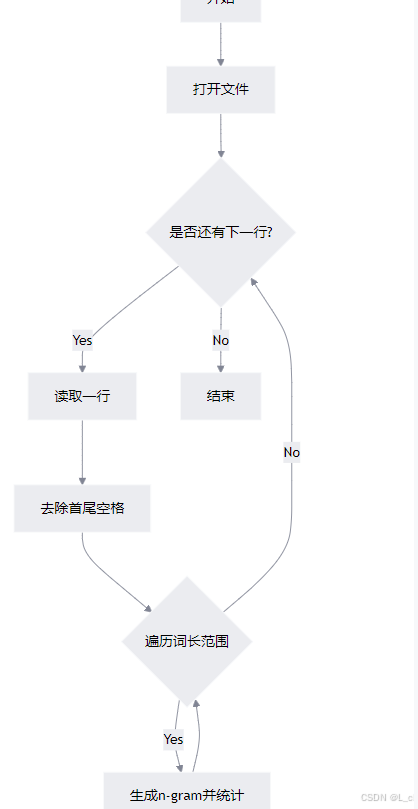
Ⅰ 打开文件:打开并读取指定路径的文件,编码为UTF-8
Ⅱ 处理文件:对文件中的每一行进行处理,去除首尾空白字符
Ⅲ 句子统计:对每个句子按不同长度(从1到self.max_word_length)进行n-gram统计
Ⅳ 计数操作:调用self.ngram_count方法进行具体的n-gram计数操作
③ 统计指定长度的词频及其左右邻居字符词频 ngram_count
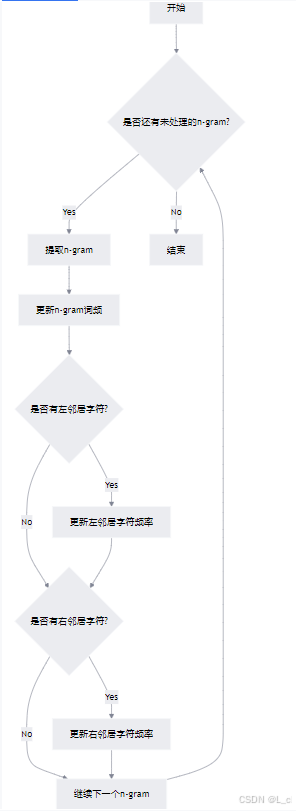
Ⅰ 遍历句子:通过循环遍历句子中的每个可能的n-gram
Ⅱ 提取n-gram:从当前索引位置提取长度为word_length的子串作为n-gram
Ⅲ 更新词频:将该n-gram的计数加1
Ⅳ 更新左邻居字符:如果存在左邻居字符,更新该n-gram的左邻居字符频率
Ⅴ 更新右邻居字符:如果存在右邻居字符,更新该n-gram的右邻居字符频率、
④ 计算熵 calc_entropy_by_word_count_dict
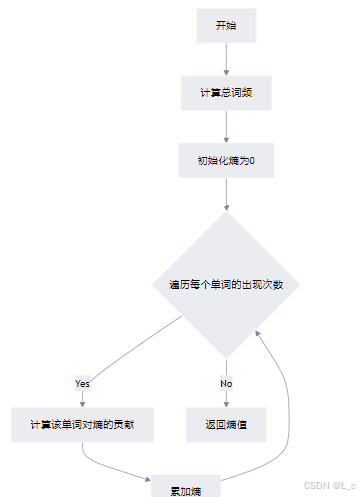
sum():通过 sum(word_count_dict.values()) 计算所有单词的总出现次数
计算熵:遍历每个单词的出现次数,使用公式 -(c / total) * math.log((c / total), 10) 计算每个单词对熵的贡献,并累加这些值
返回熵值:将计算得到的熵值返回
⑤ 计算左右熵 calc_entropy
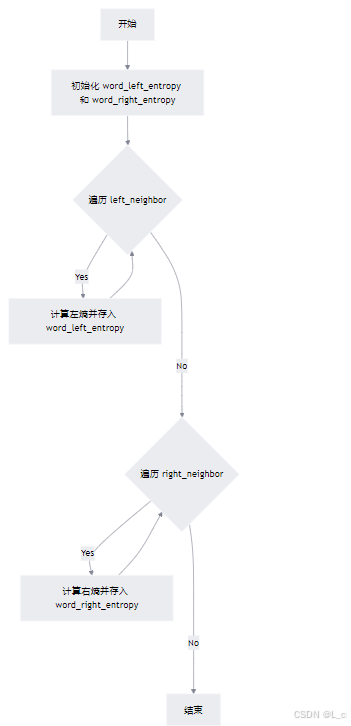
Ⅰ 初始化空字典:初始化两个空字典 self.word_left_entropy 和 self.word_right_entropy
Ⅱ 计算左熵:遍历 self.left_neighbor,对每个词调用 calc_entropy_by_word_count_dict 计算左熵,并存入 self.word_left_entropy
Ⅲ 计算右熵:遍历 self.right_neighbor,对每个词调用 calc_entropy_by_word_count_dict 计算右熵,并存入 self.word_right_entropy
⑥ 统计不同词长下的词总数 calc_total_count_by_length
.png)
Ⅰ 初始化:初始化一个默认值为0的字典 self.word_count_by_length
Ⅱ 更新不同词长下的词总数:遍历 self.word_count,对于每个单词和它的计数,根据单词长度更新 self.word_count_by_length
⑦ 计算稳固度/互信息 calc_pmi
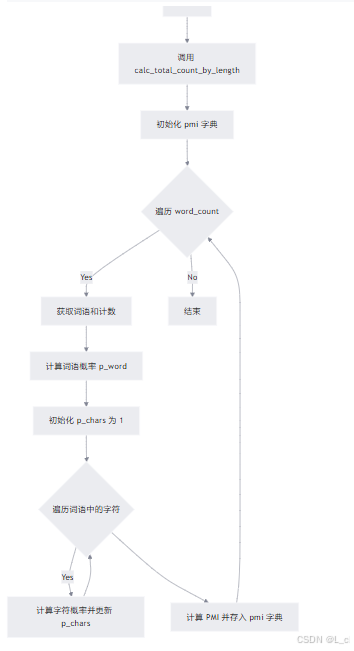
Ⅰ 初始化:调用 calc_total_count_by_length 方法,计算不同长度的词频总数
Ⅱ 初始化 PMI 字典:创建一个空字典 self.pmi
Ⅲ 遍历词语:遍历 self.word_count 中的每个词语及其出现次数
Ⅳ 计算词语概率:计算词语的概率 p_word
Ⅴ 计算字符概率乘积:计算组成该词语的每个字符的概率乘积 p_chars
Ⅵ 计算 PMI 值:根据公式 math.log(p_word / p_chars, 10) / len(word) 计算 PMI内部稳固度,并存入 self.pmi
⑧ 计算每个词的价值 calc_word_values
Ⅰ 初始化:初始化 self.word_values 为空字典
Ⅱ 遍历:
如果:① 词长度小于2 或 ② 包含逗号 或 ③ 包含句号,则跳过该词
获取词的PMI值、左熵和右熵,若不存在则设为极小值(1e-3)
使用PMI、左熵和右熵综合评估词的价值,计算公式: pmi * max(le, re)
⑨ 新词检测
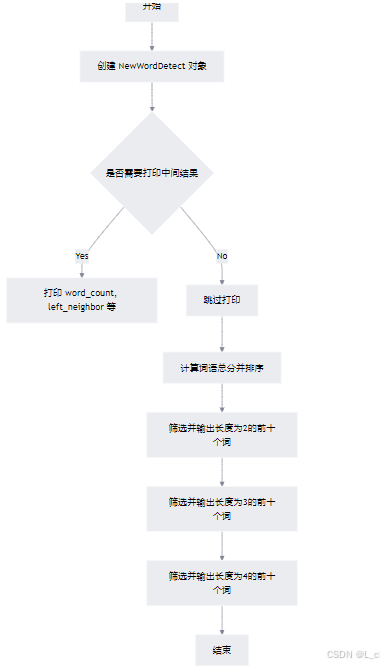
Ⅰ 初始化:创建 NewWordDetect 对象,加载语料库
Ⅱ 计算特征:计算词语的频率、左右邻词、PMI、左右熵等特征
Ⅲ 排序并输出:根据总分对词语进行排序,分别输出长度为2、3、4的前十个高分词

从词到理解
有了分词能力后,需要利用词来完成对文本的理解
首先可以想到的,就是从文章中挑选重要词
假如一个词在某类文本(假设为A类)中出现次数很多,而在其他类别文本(非A类)出现很少,那么这个词是A类文本的重要词(高权重词)
例:恒星、黑洞 ——> 天文
反之,如果一个词出现在很多领域,则其对于任意类别的重要性都很差
例:中国 ——> 政治?/地理?/经济?/足球? 你好 ——> ?/?/?/?
是否能够根据一个词来区分其属于哪个领域
TF · IDF:刻画某一个词对于某一领域的重要程度
TF:词频,某个词在某类别中出现的次数 / 该类别词的总数
IDF(N/df):逆文档频率,N:代表文本总数,dfi:代表包含词qi的文本中的总数
逆文档频率高:该词很少出现在其他文档
 ,分母+1是为了避免分母为0的情况
,分母+1是为了避免分母为0的情况
和语料库的文档总数成正比,和包含这个词的文档总数成反比
例:
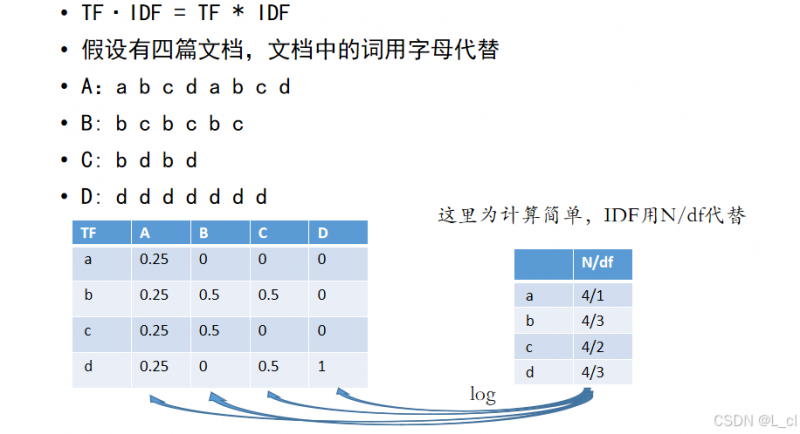
TF在某一分类的值越大,则TF项在某一分类中更为重要,例如:a只出现在A文档中,则a对A文档的标志性比较大
TF·IDF的其他计算公式:
TF:
IDF:
每个词对于每个类别都会得到一个TF·IDF值
TF·IDF高 -> 该词对于该领域重要程度高,低则相反
1.tf · idf 的计算非常依赖分词结果,如果分词出错,统计值的意义会大打折扣
2.每个词,对于每篇文档,有不同的 tf-idf 值,所以不能脱离数据讨论 tf·idf
3.假如只有一篇文本,不能计算tf·idf
4.类别数据数量均衡很重要
5.容易受各种特殊符号影响,最好做一些预处理
① 构建TF·IDF字典
Ⅰ 初始化字典:
defaultdict: 是 Python 内置的 collection 模块中的一个类,它是 的子类,提供了一种方便的方式来处理键不存在的情况。当你尝试访问 中不存在的键时,它会自动使用一个预先设定的工厂函数创建一个默认值作为该键的值,而不是像普通 那样引发 异常。
tf_dict:记录每个文档中每个词的出现频率
idf_dict:记录每个词出现在多少个文档中
Ⅱ 遍历语料库:
对于每篇文档,遍历其中的每个词,更新tf_dict和idf_dict
Ⅲ 转换idf_dict:
将idf_dict中的集合转换为文档数量
Ⅳ 返回结果:
返回tf_dict和idf_dict
② 根据tf值和idf值计算tf·idf
Ⅰ 初始化:
创建一个默认字典 tf_idf_dict 来存储每个文本中每个词的TF-IDF值
Ⅱ 遍历文本:
遍历输入的 tf_dict,其中键是文本索引,值是该文本中每个词的词频计数字典
Ⅲ 计算TF:
对于每个词,计算其在当前文本中的词频(TF),即该词出现次数除以该文本中所有词的总次数
Ⅳ 计算TF·IDF:
根据公式 tf · idf = tf * log(D / (idf + 1)) 计算TF·IDF值,其中 D 是文本总数,idf 是逆文档频率
Ⅴ 存储结果:
将计算得到的TF-IDF值存入 tf_idf_dict 中
Ⅵ 返回结果:
返回包含所有文本中每个词的TF-IDF值的字典
③ 计算给定语料库中每个文档的TF-IDF值
Ⅰ分词处理:
使用jieba.lcut对语料库中的每个文本进行分词
Ⅱ 构建TF和IDF字典:
调用build_tf_idf_dict函数,生成每个文档的词频(TF)字典和逆文档频率(IDF)字典
Ⅲ 计算TF-IDF:
调用calculate_tf_idf函数,根据TF和IDF字典计算每个文档的TF-IDF值
Ⅳ 返回结果:
返回包含每个文档TF-IDF值的字典。
④ 提取每个文本的前top个高频词
Ⅰ 初始化:
创建一个空字典topk_dict用于存储结果
Ⅱ 遍历文本:
遍历输入的tfidf_dict,对每个文本的TF-IDF值进行排序,取前top个词存入topk_dict
Ⅲ 打印输出:
如果print_word为真,则打印当前文本索引、路径及前top个词
Ⅳ 返回结果:
返回包含每个文本前top个高频词的字典
⑤ tf·idf的计算和使用

1.对于已有的所有网页(文本),计算每个网页中,词的TFIDF值
2.对于一个输入query进行分词
3.对于文档X,计算query中的词在文档X中的TFIDF值总和,作为query和文档的相关性得分
① 对于已有的所有网页(文本),计算每个网页中,词的TF·IDF值
.png)
Ⅰ 初始化:
调用 jieba.initialize() 初始化分词工具
Ⅱ 读取文件:
打开指定路径的文件,并读取其中的 JSON 数据
Ⅲ 构建语料库:
遍历每个文档,将标题和内容拼接成一个字符串,并添加到语料库列表中
Ⅳ 计算 TF-IDF:
调用 calculate_tfidf 函数,传入构建好的语料库,计算每个文档的 TF-IDF 值
Ⅴ 返回结果:
返回计算好的 TF-IDF 字典和语料库
② 对于一个输入query(查询)进行分词
对于文档X,计算query中的词在文档X中的TF·IDF值总和,作为query和文档的相关性得分
Ⅰ分词查询:使用 jieba.lcut 对输入的查询进行分词
Ⅱ 计算得分:遍历 tf_idf_dict 中的每篇文档,根据查询词在文档中的 TF-IDF 值累加得分
Ⅲ 排序结果:将所有文档按得分从高到低排序
Ⅳ 输出结果:打印得分最高的前 top 篇文档内容,并返回包含所有文档及其得分的结果列表。
③ TF·IDF实现简单搜索引擎

总结:搜索引擎是要提前将所有的网页数据进行爬取得到词表,然后再在搜索引擎内进行搜索,但是这会被所谓的数据孤岛而影响
抽取式摘要
1.通过计算TF-IDF值得到每个文本的关键词
2.将包含关键词多的句子,认为是关键句
3.挑选若干关键句,作为文本的摘要
① 加载文档数据,并计算每个文档的TF·IDF值
Ⅰ 初始化:调用 jieba.initialize() 初始化分词工具
Ⅱ 读取文件:打开并读取文件内容,解析为JSON格式的文档列表
Ⅲ 数据处理:遍历每个文档,确保标题和内容中不包含换行符,然后将标题和内容拼接成一个字符串并加入语料库
Ⅳ 计算TF-IDF:使用 calculate_tfidf 函数计算语料库的TF-IDF值
Ⅴ 返回结果:返回TF-IDF字典和语料库
② 计算生成每一篇文章的摘要
Ⅰ 句子分割:将文章按句号、问号、感叹号分割成句子列表
Ⅱ 过滤短文章:如果文章少于5个句子,返回None,因为太短的文章不适合做摘要
Ⅲ 计算句子得分:对每个句子进行分词,并根据TF-IDF词典计算句子得分
Ⅳ 排序并选择重要句子:根据句子得分排序,选择得分最高的前top个句子,并按原文顺序排列
Ⅴ 返回摘要:将选中的句子拼接成摘要返回
③ 生成文档摘要,并将摘要添加到原始文档中
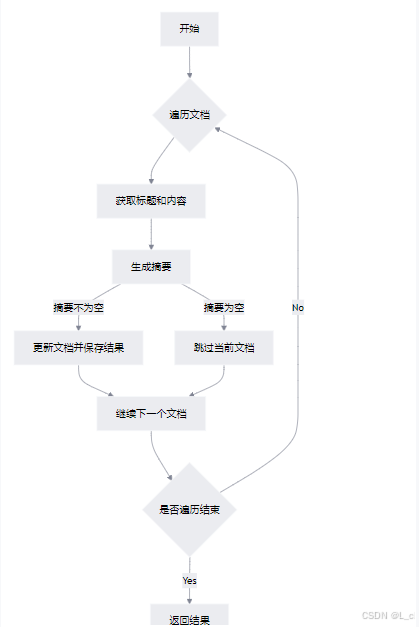
Ⅰ 初始化结果列表:创建一个空列表 res 用于存储最终的结果
Ⅱ 遍历文档:通过 tf_idf_dict.items() 遍历每个文档的TF-IDF字典
Ⅲ 分割标题和内容:从 corpus 中获取当前文档的内容,并按换行符分割为标题和正文
Ⅳ 生成摘要:调用 generate_document_abstract 函数生成摘要,如果摘要为空则跳过该文档
Ⅴ 更新文档并保存结果:将生成的摘要添加到原始文档中,并将标题、正文和摘要存入结果列表
Ⅵ 返回结果:返回包含所有文档摘要的信息列表
④ TF·IDF实现简单文本摘要

1.对所有文本计算tfidf后,从每个文本选取tfidf较高的前n个词,得到一个词的集合S。
2.对于每篇文本D,计算S中的每个词的词频,将其作为文本的向量。
3.通过计算向量夹角余弦值,得到向量相似度,作为文本的相似度
4.向量夹角余弦值计算:
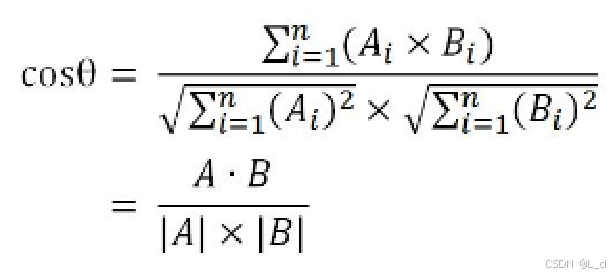
① 加载文档数据并计算TF-IDF值
Ⅰ 读取文件:从指定路径读取JSON格式的文档数据
Ⅱ 构建语料库:将每个文档的标题和内容拼接成一个字符串,存入语料库列表
Ⅲ 计算TF-IDF:调用calculate_tfidf函数计算语料库的TF-IDF值
Ⅳ 提取重要词:调用tf_idf_topk函数提取每篇文档中TF-IDF值最高的前5个词
Ⅴ 构建词汇表:将所有文档的重要词去重后存入集合,最终转换为列表
Ⅵ 返回结果:返回TF-IDF字典、词汇表和语料库。
② 将文章转换为向量
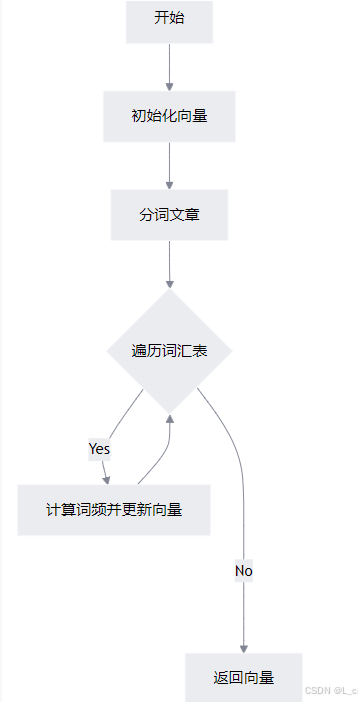
Ⅰ 初始化:初始化一个长度为词汇表大小的零向量 vector
Ⅱ 分词:使用 jieba.lcut 将文章分词为一个词语列表 passage_words
Ⅲ 更新词表:遍历词汇表中的每个词,计算其在文章中的出现频率,并更新到 vector 中
Ⅳ 返回结果:返回最终的向量
③ 文档转换为向量表示
Ⅰ 输入参数:
corpus:一个包含多个文档的列表,每个文档是一个字符串
vocab:词汇表,一个包含所有可能单词的列表
Ⅱ 处理逻辑:
使用列表推导式遍历语料库中的每个文档 c,调用 doc_to_vec 函数将其转换为向量
doc_to_vec 函数会根据词汇表 vocab 计算文档中每个词的频率,并返回一个向量表示
最终返回一个包含所有文档向量的列表 corpus_vectors
④ 计算两个向量间的余弦相似度
计算点积:通过 zip 函数将两个向量对应元素相乘并求和,得到点积 x_dot_y
计算模长:分别计算两个向量的模长 sqrt_x 和 sqrt_y
处理特殊情况:如果任一向量的模长为0,返回0
计算相似度:返回点积除以两个模长的乘积,并加上一个小常数 1e-7 防止分母为0
⑤ 计算输入文本与语料库所有文档的相似度
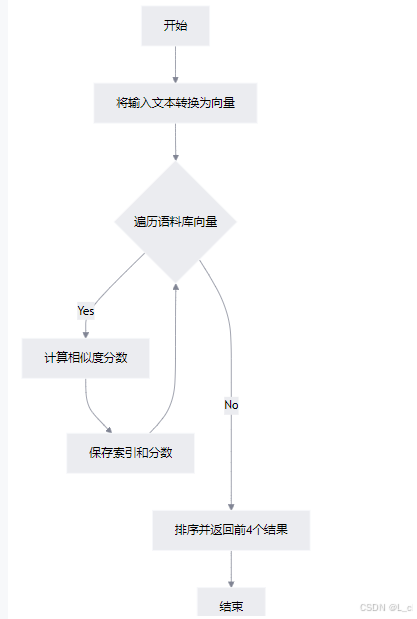
Ⅰ 将输入文本转换为向量:调用 doc_to_vec 方法,将输入文本 passage 转换为词频向量 input_vec
Ⅱ 计算相似度:遍历语料库中的每个文档向量,使用 cosine_similarity 方法计算输入向量与每个文档向量的余弦相似度
向量夹角余弦值计算公式: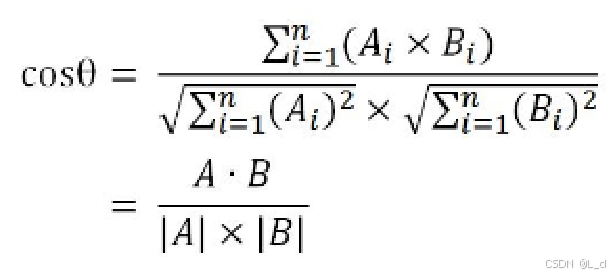
Ⅲ 排序并返回结果:将所有相似度分数按降序排列,返回前4个最相似的文档索引及其相似度分数
⑥ TF·IDF实现文本相似度计算

总结: TFIDF的计算是事先完成的,并不是实时计算,得到TFIDF的值,实际在任务中,我们需要运算的是对文档进行分词,然后将候选词的TFIDF值相加进行筛选
① 可解释性好
有具体的数据和分数,可以清晰地看到关键词
即使预测结果出错,也很容易找到原因
② 计算速度快
分词本身占耗时最多,其余为简单统计计算
③ 对标注数据依赖小
可以使用无标注语料完成一部分工作
④ 可以与很多算法组合使用
可以看做是词权重的体现
① 受分词效果影响大
分词错误会造成较大的影响
② 词与词之间没有语义相似度
同义词之间也不会进行关联,不会被同等的对待
③ 没有语序信息
TF·IDF本质上是一个词袋模型,计算搜索信息中每一个词的TF·IDF值的总和,作为搜索信息与文档信息相关性的得分
④ 能力范围有限
无法完成复杂任务,如机器翻译和实体挖掘等
深度学习可以处理几乎所有任务,只是效果好坏区别,同时可以考虑语序、考虑词与词之间的相似度、也不依赖分词的结果
⑤ 样本不均衡会对结果有很大影响
词的总数多少也会影响TF·IDF值的大小,影响结果的好坏